131 1300 0010
模型大小不斷增長(zhǎng)給現(xiàn)有架構(gòu)帶來(lái)了挑戰(zhàn)
深度學(xué)習(xí)對(duì)計(jì)算能力的需求正以驚人的速度增長(zhǎng),其近年來(lái)的發(fā)展速度已從每年翻一番縮短到每三個(gè)月翻一番。深度神經(jīng)網(wǎng)絡(luò)(DNN)模型容量的不斷提升,表明從自然語(yǔ)言處理到圖像處理的各個(gè)領(lǐng)域都得到了改進(jìn)——深度神經(jīng)網(wǎng)絡(luò)是諸如自動(dòng)駕駛和機(jī)器人等實(shí)時(shí)應(yīng)用的關(guān)鍵技術(shù)。例如,F(xiàn)acebook的研究表明,準(zhǔn)確率與模型大小的比率呈線性增長(zhǎng),通過(guò)在更大的數(shù)據(jù)集進(jìn)行訓(xùn)練,準(zhǔn)確率甚至可以得到進(jìn)一步提高。
目前在許多前沿領(lǐng)域,模型大小的增長(zhǎng)速度遠(yuǎn)快于摩爾定律,用于一些應(yīng)用的萬(wàn)億參數(shù)模型正在考慮之中。雖然很少有生產(chǎn)系統(tǒng)會(huì)達(dá)到同樣的極端情況,但在這些示例中,參數(shù)數(shù)量對(duì)性能的影響將在實(shí)際應(yīng)用中產(chǎn)生連鎖反應(yīng)。模型大小的增長(zhǎng)給實(shí)施者帶來(lái)了挑戰(zhàn)。如果不能完全依靠芯片擴(kuò)展路線圖,就需要其他解決方案來(lái)滿足對(duì)模型容量增加部分的需求,而且成本要與部署規(guī)模相適應(yīng)。這種增長(zhǎng)要求采用定制化的架構(gòu),以最大限度地發(fā)揮每個(gè)可用晶體管的性能。
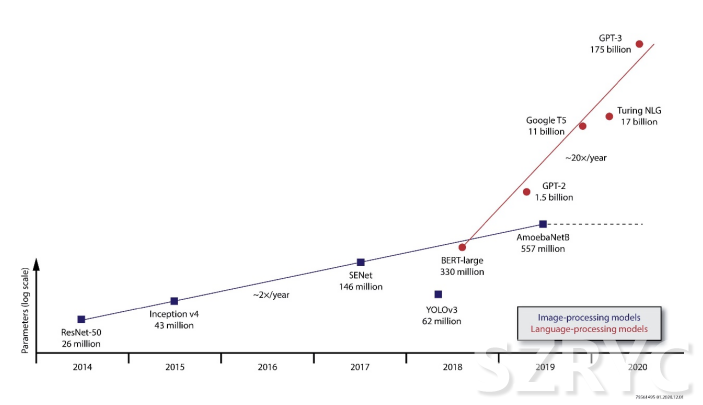
圖1:模型大小的增長(zhǎng)速度(來(lái)源:Linley Group)
Parameters (log scale):參數(shù)(對(duì)數(shù)刻度)
Image-processing models:圖像處理模型
Language-processing models:語(yǔ)言處理模型
隨著參數(shù)數(shù)量快速增長(zhǎng),深度學(xué)習(xí)架構(gòu)也在快速演進(jìn)。當(dāng)深度神經(jīng)網(wǎng)絡(luò)繼續(xù)廣泛使用傳統(tǒng)卷積、全連接層和池化層的組合時(shí),市場(chǎng)上也出現(xiàn)了其它結(jié)構(gòu),諸如自然語(yǔ)言處理(NLP)中的自注意力網(wǎng)絡(luò)。它們?nèi)匀恍枰咚倬仃嚭兔嫦驈埩康乃惴ǎ谴鎯?chǔ)訪問模式的變化可能會(huì)給圖形處理器(GPU)和當(dāng)前現(xiàn)有的加速器帶來(lái)麻煩。
結(jié)構(gòu)上的變化意味著諸如每秒萬(wàn)億次操作(TOps)等常用指標(biāo)的相關(guān)性在降低。通常情況下,處理引擎無(wú)法達(dá)到其峰值TOps分?jǐn)?shù),因?yàn)槿绻桓淖兡P偷奶幚矸绞剑鎯?chǔ)和數(shù)據(jù)傳輸基礎(chǔ)設(shè)施就無(wú)法提供足夠的吞吐量。例如,批處理輸入樣本是一種常見的方法,因?yàn)樗ǔ?梢蕴岣咴S多架構(gòu)上可用的并行性。但是,批處理增加了響應(yīng)的延遲,這在實(shí)時(shí)推理應(yīng)用中通常是不可接受的。
數(shù)值靈活性是實(shí)現(xiàn)高吞吐量的一種途徑
提高推理性能的一種途徑是使計(jì)算的數(shù)值分辨率去適應(yīng)各個(gè)獨(dú)立層的需求,這也代表了與架構(gòu)的快速演進(jìn)相適應(yīng)。一般來(lái)說(shuō),與訓(xùn)練所需的精度相比,許多深度學(xué)習(xí)模型在推理過(guò)程中可以接受明顯的精度損失和增加的量化誤差,而訓(xùn)練通常使用標(biāo)準(zhǔn)或雙精度浮點(diǎn)算法進(jìn)行。這些格式能夠在非常寬的動(dòng)態(tài)范圍內(nèi)支持高精度數(shù)值。這一特性在訓(xùn)練中很重要,因?yàn)橛?xùn)練中常見的反向傳播算法需要在每次傳遞時(shí)對(duì)許多權(quán)重進(jìn)行細(xì)微更改,以確保收斂。
通常來(lái)說(shuō),浮點(diǎn)運(yùn)算需要大量的硬件支持才能實(shí)現(xiàn)高分辨率數(shù)據(jù)類型的低延遲處理,它們最初被開發(fā)用來(lái)支持高性能計(jì)算機(jī)上的科學(xué)應(yīng)用,完全支持它所需的開銷并不是一個(gè)主要問題。
許多推理部署都將模型轉(zhuǎn)換為使用定點(diǎn)運(yùn)算操作,這大大降低了精度。在這些情況下,對(duì)準(zhǔn)確性的影響通常是最小的。事實(shí)上,有些層可以轉(zhuǎn)換為使用極其有限的數(shù)值范圍,甚至二進(jìn)制或三進(jìn)制數(shù)值也都是可行的選擇。
然而,整數(shù)運(yùn)算并不總是一種有效的解決方案。有些濾波器和數(shù)據(jù)層就需要高動(dòng)態(tài)范圍。為了滿足這一要求,整數(shù)硬件可能需要以24位或32位字長(zhǎng)來(lái)處理數(shù)據(jù),這將比8位或16位的整數(shù)數(shù)據(jù)類型消耗更多的資源,這些數(shù)據(jù)類型很容易在典型的單指令多數(shù)據(jù)(SIMD)加速器中得到支持。
一種折衷方案是使用窄浮點(diǎn)格式,例如適合16位字長(zhǎng)的格式。這種選擇可以實(shí)現(xiàn)更大的并行性,但它并沒有克服大多數(shù)浮點(diǎn)數(shù)據(jù)類型固有的性能障礙。問題在于,在每次計(jì)算后,浮點(diǎn)格式的兩部分都需要進(jìn)行調(diào)整,因?yàn)槲矓?shù)的最高有效位沒有顯式存儲(chǔ)。因此,指數(shù)的大小需要通過(guò)一系列的邏輯移位操作來(lái)調(diào)整,以確保隱含的前導(dǎo)“1”始終存在。這種規(guī)范化操作的好處是任何單個(gè)數(shù)值都只有一種表示形式,這對(duì)于用戶應(yīng)用程序中的軟件兼容性很重要。然而,對(duì)于許多信號(hào)處理和人工智能推理常規(guī)運(yùn)算來(lái)說(shuō),這是不必要的。
這些操作的大部分硬件開銷都可以通過(guò)在每次計(jì)算后無(wú)需標(biāo)準(zhǔn)化尾數(shù)和調(diào)整指數(shù)來(lái)避免。這是塊浮點(diǎn)算法所采用的方法,這種數(shù)據(jù)格式已被用于標(biāo)準(zhǔn)定點(diǎn)數(shù)字信號(hào)處理(DSP),以提高其在移動(dòng)設(shè)備的音頻處理算法、數(shù)字用戶線路(DSL)調(diào)制解調(diào)器和雷達(dá)系統(tǒng)上的性能。
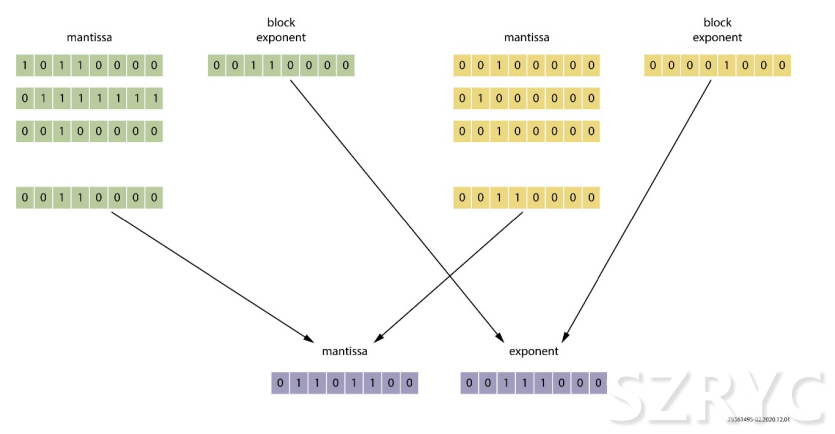
圖2:塊浮點(diǎn)計(jì)算示例
manTIssa:尾數(shù)
block exponent:塊指數(shù)
使用塊浮點(diǎn)算法,無(wú)需將尾數(shù)左對(duì)齊。用于一系列計(jì)算的數(shù)據(jù)元素可以共享相同的指數(shù),這一變化簡(jiǎn)化了執(zhí)行通道的設(shè)計(jì)。對(duì)占據(jù)相似動(dòng)態(tài)范圍的數(shù)值進(jìn)行四舍五入造成的精度損失可被降到最小。在設(shè)計(jì)時(shí)就要為每個(gè)計(jì)算塊選擇合適的范圍。在計(jì)算塊完成后,退出函數(shù)就可以對(duì)數(shù)值進(jìn)行四舍五入和標(biāo)準(zhǔn)化處理,以便在需要時(shí)將它們用作常規(guī)的浮點(diǎn)值。
支持塊浮點(diǎn)格式是機(jī)器學(xué)習(xí)處理器(MLP)的功能之一。Achronix的Speedster®7t FPGA器件和Speedcore™ eFPGA架構(gòu)提供了這種高度靈活的算術(shù)邏輯單元。機(jī)器學(xué)習(xí)處理器針對(duì)人工智能應(yīng)用所需的點(diǎn)積和類似矩陣運(yùn)算進(jìn)行了優(yōu)化。相比傳統(tǒng)浮點(diǎn),這些機(jī)器學(xué)習(xí)處理器對(duì)塊浮點(diǎn)的支持提供了實(shí)質(zhì)性的改進(jìn)。16位塊浮點(diǎn)運(yùn)算的吞吐量是傳統(tǒng)的半精度浮點(diǎn)運(yùn)算的8倍,使其與8位整數(shù)運(yùn)算的速度一樣快,與僅以整數(shù)形式的運(yùn)算相比,有功功耗僅增加了15%。
另一種可能很重要的數(shù)據(jù)類型是TensorFloat 32(TF32)格式,與標(biāo)準(zhǔn)精度格式相比,該格式的精度有所降低,但保持了較高的動(dòng)態(tài)范圍。TF32也缺乏塊指數(shù)處理的優(yōu)化吞吐量,但對(duì)于一些應(yīng)用是有用的,在這些應(yīng)用中,使用TensorFlow和類似環(huán)境所創(chuàng)建的模型的易于移植性是很重要的。Speedster7t FPGA中機(jī)器學(xué)習(xí)處理器所具有的高度靈活性使得使用24位浮點(diǎn)模式來(lái)處理TF32算法成為可能。此外,機(jī)器學(xué)習(xí)處理器的高度可配置性意味著可以支持一個(gè)全新的、塊浮點(diǎn)版本的TF32,其中四個(gè)樣本共享同一個(gè)指數(shù)。機(jī)器學(xué)習(xí)處理器支持的塊浮點(diǎn)TF32,其密度是傳統(tǒng)TF32的兩倍。
圖3:機(jī)器學(xué)習(xí)處理器(MLP)的結(jié)構(gòu)
Wireless:無(wú)線
AI/ML:人工智能/機(jī)器學(xué)習(xí)
Input Values:輸入值
Input Layer:輸入層
Hidden Layer 1:隱藏層1
Hidden Layer 2:隱藏層2
Output Layer:輸出層
處理靈活性優(yōu)化了算法支持
雖然機(jī)器學(xué)習(xí)處理器能夠支持多種數(shù)據(jù)類型,這對(duì)于推理應(yīng)用而言是至關(guān)重要的,但只有成為FPGA架構(gòu)的一部分,它的強(qiáng)大功能才能釋放出來(lái)。可輕松定義不同互連結(jié)構(gòu)的能力使FPGA從大多數(shù)架構(gòu)中脫穎而出。在FPGA中同時(shí)定義互連和算術(shù)邏輯的能力簡(jiǎn)化了構(gòu)建一種平衡架構(gòu)的過(guò)程。設(shè)計(jì)人員不僅能夠?yàn)樽远x數(shù)據(jù)類型構(gòu)建直接支持,還可以去定義最合適的互連結(jié)構(gòu),來(lái)將數(shù)據(jù)傳入和傳出處理引擎。可重編程的特性進(jìn)一步提供了應(yīng)對(duì)人工智能快速演進(jìn)的能力。通過(guò)修改FPGA的邏輯可以輕松支持自定義層中數(shù)據(jù)流的變化。
FPGA的一個(gè)主要優(yōu)勢(shì)是可以輕松地在優(yōu)化的嵌入式計(jì)算引擎和由查找表單元實(shí)現(xiàn)的可編程邏輯之間切換功能。一些功能可以很好地映射到嵌入式計(jì)算引擎上,例如Speedster7t MLP。又如,較高精度的算法最好分配給機(jī)器學(xué)習(xí)處理器(MLP),因?yàn)樵黾拥奈粚挄?huì)導(dǎo)致功能單元的大小呈指數(shù)增長(zhǎng),這些功能單元是用來(lái)實(shí)現(xiàn)諸如高速乘法之類的功能。
較低精度的整數(shù)運(yùn)算通常可以有效地分配給FPGA架構(gòu)中常見的查找表(LUT)。設(shè)計(jì)人員可以選擇使用簡(jiǎn)單的位串行乘法器電路來(lái)實(shí)現(xiàn)高延遲、高并行性的邏輯陣列。或者,他們可以通過(guò)構(gòu)建進(jìn)位保存和超前進(jìn)位的加法器等結(jié)構(gòu)來(lái)為每個(gè)功能分配更多的邏輯,這些結(jié)構(gòu)通常用來(lái)實(shí)現(xiàn)低延遲的乘法器。通過(guò)Speedster7t FPGA器件中獨(dú)特的LUT配置增強(qiáng)了對(duì)高速算法的支持,其中LUT提供了一種實(shí)現(xiàn)Booth編碼的高效機(jī)制,這是一種節(jié)省面積的乘法方法。
結(jié)果是,對(duì)于一個(gè)給定的位寬,實(shí)現(xiàn)整數(shù)乘法器所需的LUT數(shù)量可以減半。隨著機(jī)器學(xué)習(xí)中的隱私和安全性等問題變得越來(lái)越重要,應(yīng)對(duì)措施可能是在模型中部署同態(tài)加密形式。這些協(xié)議通常涉及非常適合于LUT實(shí)現(xiàn)的模式和位域操作,有助于鞏固FPGA作為人工智能未來(lái)驗(yàn)證技術(shù)的地位。
數(shù)據(jù)傳輸是吞吐量的關(guān)鍵
為了在機(jī)器學(xué)習(xí)環(huán)境中充分利用數(shù)值自定義,周圍的架構(gòu)也同樣重要。在越來(lái)越不規(guī)范的圖形表示中,能隨時(shí)在需要的地方和時(shí)間傳輸數(shù)據(jù)是可編程硬件的一個(gè)關(guān)鍵優(yōu)勢(shì)。但是,并非所有的FPGA架構(gòu)都是一樣的。
傳統(tǒng)FPGA架構(gòu)的一個(gè)問題是,它們是從早期應(yīng)用演變而來(lái)的;但在早期應(yīng)用中,其主要功能是實(shí)現(xiàn)接口和控制電路邏輯。隨著時(shí)間的推移,由于這些器件為蜂窩移動(dòng)通信基站制造商提供了一種從愈發(fā)昂貴的ASIC中轉(zhuǎn)移出來(lái)的方法,F(xiàn)PGA架構(gòu)結(jié)合了DSP模塊來(lái)處理濾波和信道估計(jì)功能。原則上,這些DSP模塊都可以處理人工智能功能。但是,這些模塊最初設(shè)計(jì)主要是用于處理一維有限沖激響應(yīng)(1D FIR)濾波器,這些濾波器使用一個(gè)相對(duì)簡(jiǎn)單的通道通過(guò)處理單元傳輸數(shù)據(jù),一系列固定系數(shù)在該通道中被應(yīng)用于連續(xù)的樣本流。
傳統(tǒng)的處理器架構(gòu)對(duì)卷積層的支持相對(duì)簡(jiǎn)單,而對(duì)其他的則更為復(fù)雜。例如,全連接層需要將一層中每個(gè)神經(jīng)元的輸出應(yīng)用到下一層的所有神經(jīng)元上。其結(jié)果是,算術(shù)邏輯單元之間的數(shù)據(jù)流比傳統(tǒng)DSP應(yīng)用中的要復(fù)雜得多,并且在吞吐量較高的情況下,會(huì)給互連帶來(lái)更大的壓力。
盡管諸如DSP內(nèi)核之類的處理引擎可以在每個(gè)周期中生成一個(gè)結(jié)果,但FPGA內(nèi)部的布線限制可能導(dǎo)致無(wú)法足夠快速地將數(shù)據(jù)傳遞給它。通常,對(duì)于專為許多傳統(tǒng)FPGA設(shè)計(jì)的、通信系統(tǒng)中常見的1D FIR濾波器來(lái)說(shuō),擁塞不是問題。每個(gè)濾波階段所產(chǎn)生的結(jié)果都可以輕松地傳遞到下一個(gè)階段。但是,張量操作所需的更高的互連以及機(jī)器學(xué)習(xí)應(yīng)用較低的數(shù)據(jù)局部性,使得互連對(duì)于任何實(shí)現(xiàn)而言都更加重要。
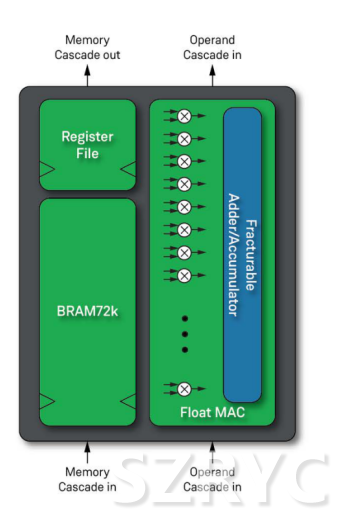
圖4:濾波器和人工智能數(shù)據(jù)流
Memory Cascade Out:存儲(chǔ)級(jí)聯(lián)輸出
Operand Cascade in:操作數(shù)級(jí)聯(lián)
Register File:寄存器文件
Fracturable:可分割
Adder/Accumulator:加法器/累加器
Memory Cascade in:存儲(chǔ)級(jí)聯(lián)
機(jī)器學(xué)習(xí)中的數(shù)據(jù)局部性問題需要注意多層級(jí)的互連設(shè)計(jì)。由于在最有效的模型中參數(shù)數(shù)量龐大,片外數(shù)據(jù)存儲(chǔ)通常是必需的。關(guān)鍵要求是可以在需要時(shí)以低延遲傳輸數(shù)據(jù)的機(jī)制,并使用靠近處理引擎的高效便箋式存儲(chǔ)器,以最有效地利用預(yù)取以及其他使用可預(yù)測(cè)訪問模式的策略,來(lái)確保數(shù)據(jù)在合適的時(shí)間可用。
在Speedster7t架構(gòu)中,有以下三項(xiàng)用于數(shù)據(jù)傳輸?shù)膭?chuàng)新:
·優(yōu)化的存儲(chǔ)層次結(jié)構(gòu)
·高效的本地布線技術(shù)
·一個(gè)用于片內(nèi)和片外數(shù)據(jù)傳輸?shù)母咚俣S片上網(wǎng)絡(luò)(2D NoC)
傳統(tǒng)的FPGA通常具有分布在整個(gè)邏輯架構(gòu)上的片上RAM塊,這些RAM塊被放置在距離處理引擎有一定距離的地方。對(duì)于典型的FPGA設(shè)計(jì)來(lái)說(shuō),這種選擇是一種有效的架構(gòu),但在人工智能環(huán)境中,它帶來(lái)了額外的和不必要的布線開銷。在Speedster7t架構(gòu)中,每個(gè)機(jī)器學(xué)習(xí)處理器(MLP)都與一個(gè)72kb的雙端口塊RAM(BRAM72k)和一個(gè)較小的2kb的雙端口邏輯RAM(LRAM2k)相關(guān)聯(lián),其中LRAM2k可以作為一個(gè)緊密耦合的寄存器文件。
可以通過(guò)FPGA布線資源分別訪問機(jī)器學(xué)習(xí)處理器(MLP)及其相關(guān)聯(lián)的存儲(chǔ)器。但是,如果一個(gè)存儲(chǔ)器正在驅(qū)動(dòng)關(guān)聯(lián)的MLP,則它可以使用直接連接,從而卸載FPGA布線資源并提供高帶寬連接。
在人工智能應(yīng)用中,BRAM可以作為一個(gè)存儲(chǔ)器,用于存儲(chǔ)那些預(yù)計(jì)不會(huì)在每個(gè)周期中發(fā)生變化的值,諸如神經(jīng)元權(quán)重和激活值。LRAM更適合存儲(chǔ)只有短期數(shù)據(jù)局部性的臨時(shí)值,諸如輸入樣本的短通道以及用于張量收縮和池化活動(dòng)的累積值。
該架構(gòu)考慮到需要能夠?qū)⒋笮蛷?fù)雜的層劃分為可并行操作的段,并為每個(gè)段提供臨時(shí)數(shù)據(jù)值。BRAM和LRAM都具有級(jí)聯(lián)連接功能,可輕松支持機(jī)器學(xué)習(xí)加速器中常用的脈動(dòng)陣列的構(gòu)建。
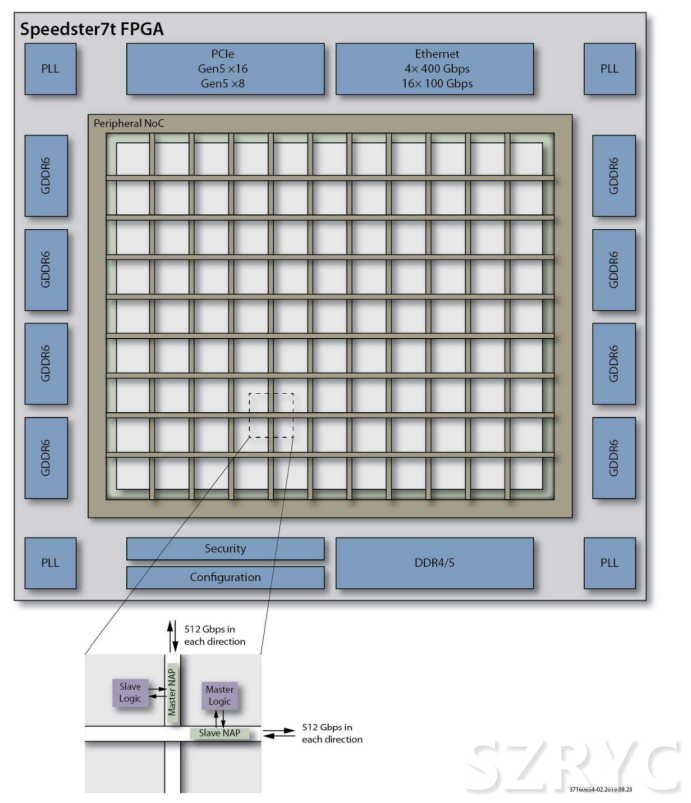
圖5:具有存儲(chǔ)和級(jí)聯(lián)連接功能的MLP
MLP可以從邏輯陣列、共享數(shù)據(jù)的級(jí)聯(lián)路徑以及關(guān)聯(lián)的BRAM72k和LRAM2k逐周期驅(qū)動(dòng)。這種安排能夠構(gòu)建復(fù)雜的調(diào)度機(jī)制和數(shù)據(jù)處理通道,使MLP持續(xù)得到數(shù)據(jù)支持,同時(shí)支持神經(jīng)元之間盡可能廣泛的連接模式。為MLP持續(xù)提供數(shù)據(jù)是提高有效TOps算力的關(guān)鍵。
MLP的輸出具有同樣的靈活性,能夠創(chuàng)建脈動(dòng)陣列和更復(fù)雜的布線拓?fù)洌瑥亩鵀樯疃葘W(xué)習(xí)模型中可能需要的每種類型的層提供優(yōu)化的架構(gòu)。
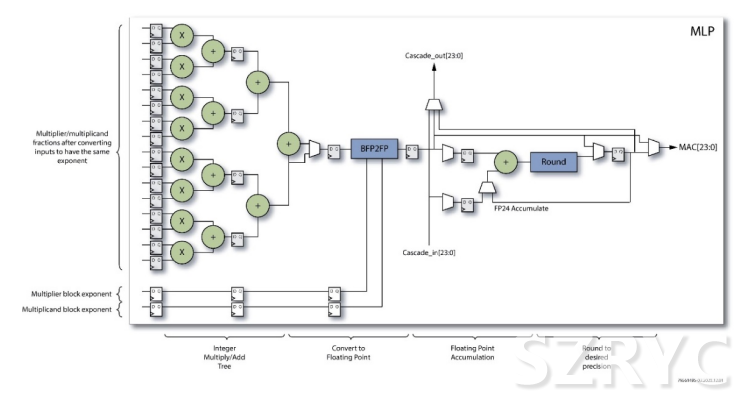
MulTIplier / mulTIplicand fracTIons after converting inputs to have the same exponent:將輸入轉(zhuǎn)換為具有相同指數(shù)后的乘數(shù)/被乘數(shù)分?jǐn)?shù)
Multiplier block exponent:乘數(shù)塊指數(shù)
Multiplicand block exponent:被乘數(shù)塊指數(shù)
Integer Multiply / Add Tree:整數(shù)乘法/加法樹:
Convert to Floating Point:轉(zhuǎn)換為浮點(diǎn)
Floating Point Accumulation:浮點(diǎn)累加
Round to desired precision:四舍五入到所需精度
Speedster7t架構(gòu)中的2D NoC提供了從邏輯陣列的可編程邏輯到位于I/O環(huán)中的高速接口子系統(tǒng)的高帶寬連接,用于連接到片外資源。它們包括用于高速存儲(chǔ)訪問的GDDR6和諸如PCIe Gen5和400G以太網(wǎng)等片內(nèi)互連協(xié)議。這種結(jié)構(gòu)支持構(gòu)建高度并行化的架構(gòu),以及基于中央FPGA的高度數(shù)據(jù)優(yōu)化的加速器。
通過(guò)將高密度數(shù)據(jù)包路由到分布在整個(gè)邏輯陣列上的數(shù)百個(gè)接入點(diǎn),2D NoC使得大幅增加FPGA上的可用帶寬成為可能。傳統(tǒng)的FPGA必須使用數(shù)千個(gè)單獨(dú)編程的布線路徑來(lái)實(shí)現(xiàn)相同的吞吐量,而這樣做會(huì)大量吃掉本地的互連資源。通過(guò)網(wǎng)絡(luò)接入點(diǎn)將千兆數(shù)據(jù)傳輸?shù)奖镜貐^(qū)域,2D NoC緩解了布線問題,同時(shí)支持輕松而快速地將數(shù)據(jù)傳入和傳出MLP和基于LUT的定制化處理器。
相關(guān)的資源節(jié)省是相當(dāng)可觀的——一個(gè)采用傳統(tǒng)FPGA軟邏輯實(shí)現(xiàn)的2D NoC具有64個(gè)NoC接入點(diǎn)(NAP),每個(gè)接入點(diǎn)提供一個(gè)運(yùn)行頻率為400MHz的128位接口,將消耗390kLUT。相比之下,Speedster 7t1500器件中的硬2D NoC具有80個(gè)NAP,不消耗任何FPGA軟邏輯,并且提供了更高的帶寬。
使用2D NoC還有其他的一些優(yōu)勢(shì)。由于相鄰區(qū)域之間互連擁塞程度較低,因此邏輯設(shè)計(jì)更易于布局。因?yàn)闊o(wú)需從相鄰區(qū)域分配資源來(lái)實(shí)現(xiàn)高帶寬路徑的控制邏輯,因此設(shè)計(jì)也更加有規(guī)律。另一個(gè)好處是極大地簡(jiǎn)化了局部性重新配置——NAP支持單個(gè)區(qū)域成為有效的獨(dú)立單元,這些單元可以根據(jù)應(yīng)用的需要進(jìn)行交換導(dǎo)入和導(dǎo)出。這種可重配置的方法反過(guò)來(lái)又支持需要在特定時(shí)間使用的不同模型,或者支持片上微調(diào)或定期對(duì)模型進(jìn)行再訓(xùn)練這樣的架構(gòu)。
結(jié)論
隨著模型增大和結(jié)構(gòu)上變得更加復(fù)雜,F(xiàn)PGA正成為一種越來(lái)越具吸引力的基礎(chǔ)器件來(lái)構(gòu)建高效、低延遲AI推理解決方案,而這要?dú)w功于其對(duì)多種數(shù)值數(shù)據(jù)類型和數(shù)據(jù)導(dǎo)向功能的支持。但是,僅僅將傳統(tǒng)的FPGA應(yīng)用于機(jī)器學(xué)習(xí)中是遠(yuǎn)遠(yuǎn)不夠的。機(jī)器學(xué)習(xí)以數(shù)據(jù)為中心的特性需要一種平衡的架構(gòu),以確保性能不受人為限制。考慮到機(jī)器學(xué)習(xí)的特點(diǎn),以及不僅是現(xiàn)在,而且在其未來(lái)的開發(fā)需求,Achronix Speedster7t FPGA為AI推理提供了理想的基礎(chǔ)器件。

