131 1300 0010
HDFS(HadoopDistributedFileSystem),是一個適合運行在通用硬件(commodityhardware)上的分布式文件系統,是Hadoop的核心子項目,是基于流數據模式訪問和處理超大文件的需求而開發的。該系統仿效了谷歌文件系統(GFS),是GFS的一個簡化和開源版本。
HDFS的主要架構
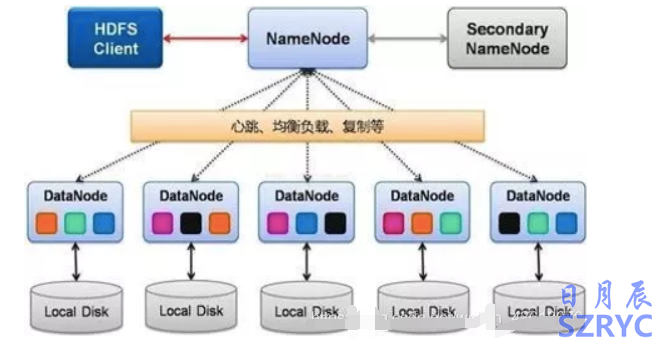
HDFSClient(客戶端):從NameNode獲取文件的位置信息,再從DataNode讀取或者寫入數據。此外,client在數據存儲時,負責文件的分割;
NameNode(元數據節點):管理名稱空間、數據塊(Block)映射信息、配置副本策略、處理客戶端讀寫請求;
DataNode(存儲節點):負責執行實際的讀寫操作,存儲實際的數據塊,同一個數據塊會被存儲在多個DataNode上
SecondaryNameNode:定期合并元數據,推送給NameNode,在緊急情況下,可輔助NameNode的HA恢復。
HDFS的特點(VsGFS)
分塊更大,每個數據塊默認128MB;
不支持并發,同一時刻只允許一個寫入者或追加者;
過程一致性,寫入數據的傳輸順序與最終寫入順序一致;
MasterHA,2.X版本支持兩個NameNode,(分別處于AcTIve和Standby狀態),故障切換時間一般幾十秒到數分鐘
HDFS適合的應用場景:
適用于大文件、大數據處理,處理數據達到GB、TB、甚至PB級別的數據。
適合流式文件訪問,一次寫入,多次讀取。
文件一旦寫入不能修改,只能追加。
HDFS不適合的場景:
低延時數據訪問。
小文件存儲
并發寫入、文件隨機修改

