131 1300 0010
嵌入式Linux啟動時間優化的秘密
01
工具鏈/應用程序優化
導讀:嵌入式Linux在應用中往往希望系統能在盡量短的時間內啟動,以提高用戶體驗。而且在有的應用場合,對啟動時間具有嚴格的時間要求,尤其在工業或者醫療器械應用領域。此時如何加快Linux的啟動,將成為一個挑戰,對于大多數應用開發人員而言,由于Linux系統的復雜性,對于如何提高啟動速度,往往無從下手。那么閱讀完本文,將獲得清晰完整的解決思路。
1.降低啟動時間的一般思路
在準備降低系統的啟動時間時,思路上應建立以下的切入點:
最快的代碼是未執行的代碼。
引導操作本質上的很大一部分工作實際上是將代碼和數據從存儲設備加載到RAM。如所需加載內容越少則意味著加載操作越快。
如果根文件系統越大,則安裝時間可能會越長。
因此,即使未執行的代碼也會延長啟動時間。
另外在硬件方案設計時盡量選擇讀寫速度快的存儲介質。例如,從SD卡啟動實際上比從NAND FLASH啟動快。
2.啟動時間測量方法
要降低系統的啟動時間,則首先需要選擇一個可靠的啟動時間的測量方法:
在Linux代碼中加入對某一個GPIO腳的邏輯電平控制,利用示波器測量GPIO狀態。后面將介紹如何在代碼中加入對GPIO的控制。
監控串口控制臺報文以測量時間,可以使用grabserial。
參見https://elinux.org/Grabserial
3. 工具鏈優化
3.1 從工具鏈入手
選擇使用合適的工具鏈,應是第一個入手點,因為所有的運行加載固件都是由工具鏈編譯而成。如果尚未進行其他優化,則更改工具鏈的好處將更加明顯,并且更容易度量。
您可以在工具鏈中進行以下更改,這可能會影響啟動時間,性能和大小:
編譯器版本:gcc和binutils的版本,最新版本往往可以具有更好的優化功能。
C庫:glibc,uClibc,musl。使用uClibc和musl庫編譯的根文件系統更小
指令集變量:ARM或Thumb2,是否支持硬浮點。
可能會影響代碼性能和代碼大小(Thumb2編碼與ARM相同的指令,但以更緊湊的方式,至少會顯著減小大小)。
C庫在創建工具鏈時進行了硬編碼,可供選擇的C庫:
glibc:最標準且功能最全。http://www.gnu.org/software/libc/
uClibc:更小且可配置。已經存在約20年了。http://uclibc-ng.org/
musl:uClibc替代品,雖比較新但很成熟。http://www.musl-libc.org/
可以對glibc/uclibc-ng /musl進行對比測試:
1.靜態編譯hello.c程序并比較大小
使用gcc 6.3, armel, musl 1.1.16: 7300 字節
使用gcc 6.3, armel, uclibc-ng 1.0.22 : 67204 字節
使用gcc 6.2, armel, glibc: 492792 字節
2. 靜態編譯BusyBox 1.26.2并比較大小
使用gcc 6.3, armel, musl 1.1.16: 183348 字節
使用gcc 6.3, armel, uclibc-ng 1.0.22 : 210620 字節
使用gcc 6.2, armel, glibc: 755088 字節
3.2 指令集選擇
編譯rootfs進行測試對比:
用gcc 7.4編譯,生成ARM代碼:
根文件系統總大小:3.79 MB
用gcc 7.4編譯,生成Thumb2代碼:
根文件系統總大小:3.10 MB(-18%)
性能方面:Thumb2的性能明顯改善(大約少于5%,但是從一次運行到另一次運行,測量的執行時間略有變化)。
4. 應用軟件優化
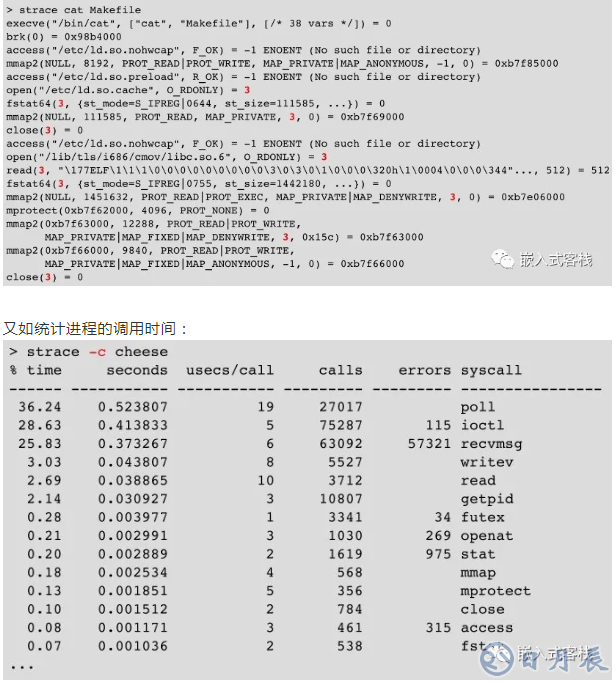
4.1 測量strace
strace允許跟蹤應用程序及其子級進行的所有系統調用。對于開發非常有用:
了解如何在用戶空間上花費時間
例如,輕松查找打開嘗試(open()),文件訪問(read() /write() )和內存分配(mmap2() )。無需訪問源代碼即可完成!
尋找耗時最長的開銷應用
查找在應用程序和腳本中完成的不必要的工作。例如:多次打開同一文件,或嘗試打開不存在的文件。
局限性:您無法跟蹤init進程!
關于strace 參見
http://sourceforge.net/projects/strace/:
在所有GNU / Linux系統上可用,可以由您的交叉編譯工具鏈生成器構建。
更簡單的辦法:直接拷貝一個現成的靜態二進制文件。 參見
https://github.com/bootlin/staTIc-binaries/tree/master/strace
可以查看進程的操作情況:
1. 訪問文件,分配內存。。.
2. 通常足以發現簡單的錯誤。
用法:
1.strace 《命令》(開始一個新進程)
2.strace -p 《pid》(跟蹤現有進程)strace -c 《command》(統計進程的系統開銷時間)
如查看cat操作:
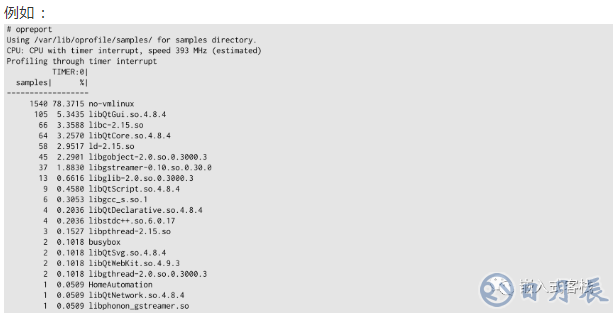
4.2 Linux上的性能監測工具oprofile
Oprofile是linux上的性能監測工具:
具有兩種工作方式:legacy模式和perf_events模式
legacy模式:
1.精度低,請使用內核驅動程序進行配置
2.使用CONFIG_OPROFILE進行編譯配置
3.用戶空間工具:opcontrol和oprofiled
perf_events模式:
1.使用硬件性能計數器
2.使用CONFIG_PERF_EVENTS和CONFIG_HW_PERF_EVENTS編譯配置
3.用戶空間工具:operf
其使用方法:
legacy 模式:
opcontrol --vmlinux=/path/to/vmlinux # opTIonal step
opcontrol --start
/my/command
opcontrol --stop
perf_events 模式
operf --vmlinux=/path/to/vmlinux /my/command
利用opreport獲取結果
4.3 perf工具
Perf 是內置于Linux 內核源碼樹中的性能剖析(profiling)工具。它基于事件采樣原理,以性能事件為基礎,支持針對處理器相關性能指標與操作系統相關性能指標的性能剖析。可用于性能瓶頸的查找與熱點代碼的定位。linux2.6及后續版本都自帶該工具,幾乎能夠處理所有與性能相關的事件
使用硬件性能計數器
使用CONFIG_PERF_EVENTS和CONFIG_HW_PERF_EVENTS進行配置
用戶空間工具:性能。它是內核源代碼的一部分,因此始終與您的內核同步。
用法:perf record /my/command
通過以下方式獲得結果:perf report

4.4 連接器優化
啟動時使用的應用程序組代碼:
查找啟動期間調用的功能,例如使用
-finstrument-funcTIons gcc選項。
創建一個自定義的鏈接描述文件,以按調用順序重新排列這些函數。可以通過將每個函數放在各自的部分中來實現:
-ffuncTIon-sections gcc選項。
特別對于具有較大MTD讀取塊的閃存存儲特別有用。因為讀取整個讀取塊后,極有可能讀取不必要的數據。
詳細信息:http://blogs.linux.ie/caolan/2007/04/24/controlling-symbol-ordering/
通過如下方法,可以找到有望被優化的地方:
1.啟動一次應用程序并測量其啟動時間。
2.再次啟動應用程序并測量其啟動時間。由于它的代碼應仍在Linux文件緩存中,故其代碼加載時間將為零。
從而知道第一次加載應用程序代碼(及其庫)所花費的時間。鏈接器優化節省的時間應少于此上限。
然后據此可以決定是否有必要這樣對該應用進行鏈接優化。由于鏈接優化必須修改應用程序的編譯方式,因此此類優化的成本很高。
4.4.1 Prelink 預鏈接工具
Prelink是Red Hat 開發者 Jakub Jelinek 所設計的工具,正如其名字所示,Prelink利用事先鏈接代替運行時鏈接的方法來加速共享庫的加載,它不僅可以加快起動速度,還可以減少部分內存開銷,是各種Linux架構上用于減少程序加載時間、縮短系統啟動時間和加快應用程序啟動的很受歡迎的一個工具。
預鏈接減少了啟動可執行文件所需的時間
在Android上廣泛使用
必須配置為知道哪些庫需要進行預鏈接,并將為每個可用符號分配一個固定的地址,從而消除了在啟動可執行文件時重新定位符號的需要。
請注意安全性,因為可執行代碼始終加載在同一地址。
代碼以及文檔參見
http://people.redhat.com/jakub/prelink/
支持ARM,但自2013年以來未發布。Buildroot也不支持。但是,x86比較容易實現。
工具鏈/應用程序優化的部分就在此結束了,下篇我們將繼續講嵌入式Linux啟動時間優化的方法之文件系統,請大家繼續關注我們電子發燒友網和嵌入式客棧。

