131 1300 0010
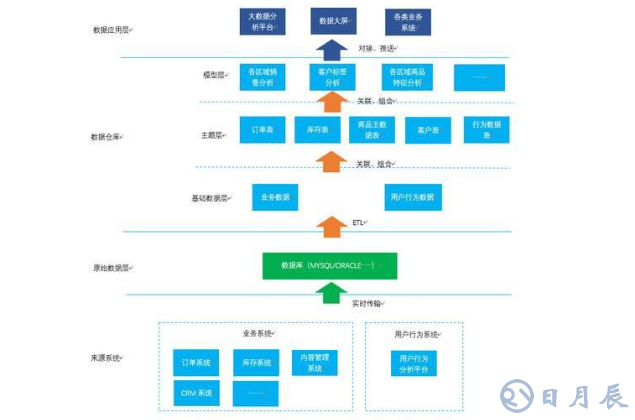
數(shù)據(jù)倉庫并不是獨立存在的一個個體,而是與整個大數(shù)據(jù)體系融為一體的——換句話說,數(shù)據(jù)倉庫就像人的心臟,人只有心臟而沒有其他器官是無法單獨存活下來的。數(shù)據(jù)的來源系統(tǒng),可以理解為數(shù)據(jù)的收集系統(tǒng)。顧名思義,即存放從來源系統(tǒng)過來的原始數(shù)據(jù),所謂原始數(shù)據(jù)——即未經(jīng)過任何加工處理的數(shù)據(jù)。
這一層次咋看之下有點多余,但實際上是有所考量的:
1)將數(shù)據(jù)倉庫與業(yè)務(wù)系統(tǒng)分隔開
數(shù)據(jù)倉庫的數(shù)據(jù),實時性要求不高,而準(zhǔn)確性、清潔型必須較高,因此清洗的腳本繁多。如果每條數(shù)據(jù)都實時傳送到數(shù)據(jù)倉庫的話,那腳本執(zhí)行的頻率將非常高,所占用的系統(tǒng)資源也隨之增加。
2)分擔(dān)業(yè)務(wù)系統(tǒng)的報表任務(wù)
總所周知,搭建大數(shù)據(jù)體系架構(gòu)所使用的硬件資源是相對較高的,而業(yè)務(wù)系統(tǒng)往往只是支撐業(yè)務(wù)持續(xù)開展,從性能上往往無法支撐大數(shù)據(jù)量報表的導(dǎo)出。因此,原始數(shù)據(jù)層可以承載此項功能,業(yè)務(wù)系統(tǒng)數(shù)據(jù)傳輸?shù)膶崟r性也保證了從原始數(shù)據(jù)層導(dǎo)出的數(shù)據(jù)符合業(yè)務(wù)人員對報表實時性的需要。
一般來說,數(shù)據(jù)倉庫可區(qū)分為三層:基礎(chǔ)數(shù)據(jù)層、主題層、模型層原始數(shù)據(jù)層以天為時間周期,將每天的數(shù)據(jù)傳輸?shù)綌?shù)據(jù)倉庫,數(shù)據(jù)倉庫通過ETL(抽取、轉(zhuǎn)化、加載)的方式,將數(shù)據(jù)按照設(shè)定的數(shù)據(jù)表格式存儲好,形成基礎(chǔ)數(shù)據(jù)層的數(shù)據(jù)。
ETL即:Extra、Transfer、Load——簡單來說,即數(shù)據(jù)清洗。先將數(shù)據(jù)抽取出來,將冗余數(shù)據(jù),錯誤數(shù)據(jù),有歧義的數(shù)據(jù)按照既定的規(guī)則進(jìn)行刪減、填充、修改,再填充入已設(shè)定好的表結(jié)構(gòu)的數(shù)據(jù)庫表中。
數(shù)據(jù)清洗就像打掃衛(wèi)生一樣,將不要的東西扔掉,將破舊的東西擦拭干凈,但并不代表數(shù)據(jù)是完整的。主題層的構(gòu)建相對復(fù)雜,搭建的規(guī)則主要是看未來的需要以及產(chǎn)品經(jīng)理對業(yè)務(wù)的理解。數(shù)據(jù)來到模型層,也就意味著他們最終要成為“炮彈”,發(fā)射到數(shù)據(jù)分析平臺了,因此模型層的最主要作用是:將主題數(shù)據(jù)組合成數(shù)據(jù)分析模型。

假設(shè)我們需要在數(shù)據(jù)分析平臺上體現(xiàn)出“不同商品在不同區(qū)域不同客戶的熱銷情況”,那在模型層就需要以訂單表作為最基礎(chǔ)的表,關(guān)聯(lián)上區(qū)域表、客戶表、商品表,關(guān)聯(lián)出一個以區(qū)域+商品+客戶特征維度劃分的明細(xì)數(shù)據(jù)。每個區(qū)域每個商品每個客戶對應(yīng)一行銷售數(shù)據(jù),根據(jù)這份數(shù)據(jù)匯總出一個按區(qū)域+商品+客戶特征的模型,輸出到數(shù)據(jù)分析平臺,展示出不同區(qū)域,不同商品的客戶特征是怎樣的。
需要注意的是:模型層的數(shù)據(jù)都是呈現(xiàn)出星狀結(jié)構(gòu)和高度索引化的。因為在大數(shù)據(jù)平臺上,數(shù)據(jù)與數(shù)據(jù)之間往往是需要存在關(guān)聯(lián)的,運營人員看到商品在不同區(qū)域上的銷量分布,往往也想進(jìn)一步看到在不同區(qū)域上的商品有什么特征,客戶有什么特征,這些都需要和區(qū)域強關(guān)聯(lián)起來的。
數(shù)據(jù)應(yīng)用層嚴(yán)格意義上不屬于大數(shù)據(jù)架構(gòu),因為它除了會涉及各式各樣的數(shù)據(jù)分析平臺,還會涉及到業(yè)務(wù)系統(tǒng)。上文提到過,業(yè)務(wù)系統(tǒng)對于數(shù)據(jù)倉庫而言更多是作為數(shù)據(jù)收集工具,但同時業(yè)務(wù)系統(tǒng)也存在著數(shù)據(jù)的需求,我把這樣的過程稱為數(shù)據(jù)反哺。
往往支撐公司業(yè)務(wù)開展下去的業(yè)務(wù)系統(tǒng)不止一個,很可能是有多個,而各式各樣的業(yè)務(wù)系統(tǒng)之間也需要數(shù)據(jù)交互。例如:一般電商公司會有一套前端商家平臺,也會一套后端的管理平臺,這兩套平臺使用的往往不是同一套SKU,因此需要將后端SKU同步到前端來進(jìn)行mapping。
那么為什么不能直接讓這兩套系統(tǒng)直接進(jìn)行數(shù)據(jù)交互呢?因為數(shù)據(jù)已經(jīng)不再干凈,需要數(shù)據(jù)倉庫進(jìn)行清洗過后,將冗余的數(shù)據(jù)去除后方可推送至前端商家平臺。
數(shù)據(jù)倉庫的數(shù)據(jù),最終除了會流向業(yè)務(wù)系統(tǒng)以外,更多的會流向各大數(shù)據(jù)應(yīng)用系統(tǒng),即:數(shù)據(jù)大屏,大數(shù)據(jù)分析平臺等此時的數(shù)據(jù),已經(jīng)過層層清洗加工、模型搭建,形成一個個炮彈,通過接口的形式推送至各大數(shù)據(jù)平臺。對于這些數(shù)據(jù)分析、數(shù)據(jù)展示平臺而言,更多的只需要考慮如何直觀展示數(shù)據(jù)即可。

