131 1300 0010
CPU和GPU之所以大不相同,是由于其設(shè)計(jì)目標(biāo)的不同,它們分別針對了兩種不同的應(yīng)用場景。CPU需要很強(qiáng)的通用性來處理各種不同的數(shù)據(jù)類型,同時(shí)又要邏輯判斷又會引入大量的分支跳轉(zhuǎn)和中斷的處理。這些都使得CPU的內(nèi)部結(jié)構(gòu)異常復(fù)雜。而GPU面對的則是類型高度統(tǒng)一的、相互無依賴的大規(guī)模數(shù)據(jù)和不需要被打斷的純凈的計(jì)算環(huán)境。

這個視頻,非常具象的表述了CPU和GPU在圖像處理時(shí)的不同的原理和方法。看到GPU的模型噴射出的一瞬間,你就秒懂了。
根據(jù)上面視頻中的比喻,你應(yīng)該很清楚CPU和GPU就呈現(xiàn)出非常不同的架構(gòu):
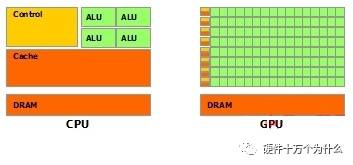
綠色的是計(jì)算單元
橙紅色的是存儲單元
橙黃色的是控制單元
GPU采用了數(shù)量眾多的計(jì)算單元和超長的流水線,但只有非常簡單的控制邏輯并省去了Cache。而CPU不僅被Cache占據(jù)了大量空間,而且還有有復(fù)雜的控制邏輯和諸多優(yōu)化電路,相比之下計(jì)算能力只是CPU很小的一部分。
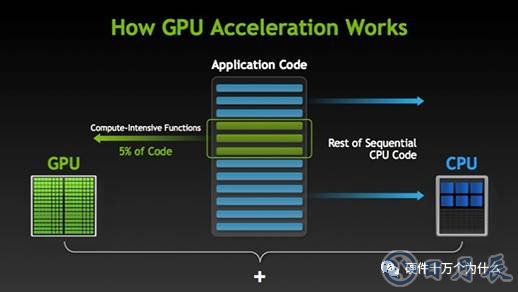
GPU 如何加快軟件應(yīng)用程序的運(yùn)行速度
GPU 加速計(jì)算可以提供非凡的應(yīng)用程序性能,能將應(yīng)用程序計(jì)算密集部分的工作負(fù)載轉(zhuǎn)移到 GPU,同時(shí)仍由 CPU 運(yùn)行其余程序代碼。從用戶的角度來看,應(yīng)用程序的運(yùn)行速度明顯加快.
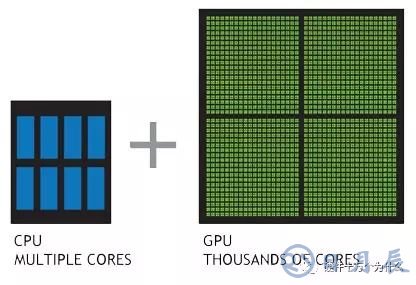
GPU 與 CPU 性能比較
理解 GPU 和 CPU 之間區(qū)別的一種簡單方式是比較它們?nèi)绾翁幚砣蝿?wù)。CPU 由專為順序串行處理而優(yōu)化的幾個核心組成,而 GPU 則擁有一個由數(shù)以千計(jì)的更小、更高效的核心(專為同時(shí)處理多重任務(wù)而設(shè)計(jì))組成的大規(guī)模并行計(jì)算架構(gòu)。
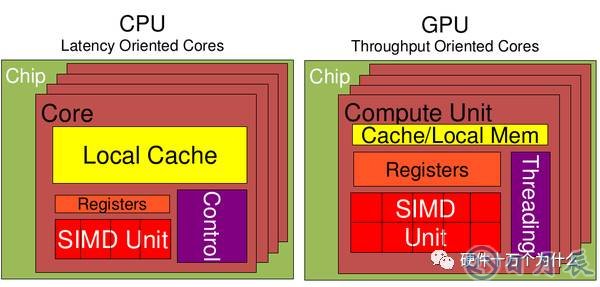
從上圖可以看出:
Cache, local memory: CPU > GPU
Threads(線程數(shù)): GPU > CPU
Registers: GPU > CPU
SIMD Unit(單指令多數(shù)據(jù)流,以同步方式,在同一時(shí)間內(nèi)執(zhí)行同一條指令): GPU > CPU。
CPU 基于低延時(shí)的設(shè)計(jì):
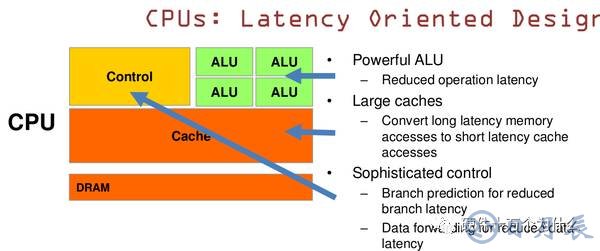
CPU有強(qiáng)大的ALU(算術(shù)運(yùn)算單元),它可以在很少的時(shí)鐘周期內(nèi)完成算術(shù)計(jì)算。
當(dāng)今的CPU可以達(dá)到64bit 雙精度。執(zhí)行雙精度浮點(diǎn)源算的加法和乘法只需要1~3個時(shí)鐘周期。
CPU的時(shí)鐘周期的頻率是非常高的,達(dá)到1.532~3gigahertz(千兆HZ, 10的9次方).
大的緩存也可以降低延時(shí)。保存很多的數(shù)據(jù)放在緩存里面,當(dāng)需要訪問的這些數(shù)據(jù),只要在之前訪問過的,如今直接在緩存里面取即可。
復(fù)雜的邏輯控制單元。當(dāng)程序含有多個分支的時(shí)候,它通過提供分支預(yù)測的能力來降低延時(shí)。
數(shù)據(jù)轉(zhuǎn)發(fā)。 當(dāng)一些指令依賴前面的指令結(jié)果時(shí),數(shù)據(jù)轉(zhuǎn)發(fā)的邏輯控制單元決定這些指令在pipeline中的位置并且盡可能快的轉(zhuǎn)發(fā)一個指令的結(jié)果給后續(xù)的指令。這些動作需要很多的對比電路單元和轉(zhuǎn)發(fā)電路單元。
GPU是基于大的吞吐量設(shè)計(jì)
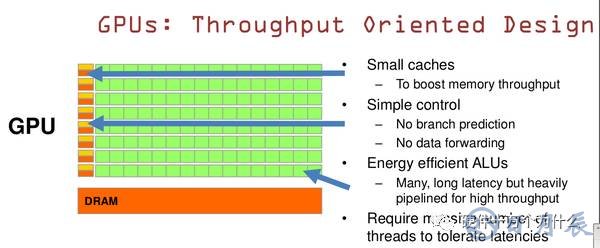
GPU的特點(diǎn)是有很多的ALU和很少的cache. 緩存的目的不是保存后面需要訪問的數(shù)據(jù)的,這點(diǎn)和CPU不同,而是為thread提高服務(wù)的。如果有很多線程需要訪問同一個相同的數(shù)據(jù),緩存會合并這些訪問,然后再去訪問dram(因?yàn)樾枰L問的數(shù)據(jù)保存在dram中而不是cache里面),獲取數(shù)據(jù)后cache會轉(zhuǎn)發(fā)這個數(shù)據(jù)給對應(yīng)的線程,這個時(shí)候是數(shù)據(jù)轉(zhuǎn)發(fā)的角色。但是由于需要訪問dram,自然會帶來延時(shí)的問題。
GPU的控制單元(左邊黃色區(qū)域塊)可以把多個的訪問合并成少的訪問。
GPU的雖然有dram延時(shí),卻有非常多的ALU和非常多的thread. 為啦平衡內(nèi)存延時(shí)的問題,我們可以中充分利用多的ALU的特性達(dá)到一個非常大的吞吐量的效果。盡可能多的分配多的Threads.通常來看GPU ALU會有非常重的pipeline就是因?yàn)檫@樣。
所以與CPU擅長邏輯控制,串行的運(yùn)算。和通用類型數(shù)據(jù)運(yùn)算不同,GPU擅長的是大規(guī)模并發(fā)計(jì)算,這也正是密碼破解等所需要的。所以GPU除了圖像處理,也越來越多的參與到計(jì)算當(dāng)中來。
GPU的工作大部分就是這樣,計(jì)算量大,但沒什么技術(shù)含量,而且要重復(fù)很多很多次。就像你有個工作需要算幾億次一百以內(nèi)加減乘除一樣,最好的辦法就是雇上幾十個小學(xué)生一起算,一人算一部分,反正這些計(jì)算也沒什么技術(shù)含量,純粹體力活而已。而CPU就像老教授,積分微分都會算,就是工資高,一個老教授資頂二十個小學(xué)生,你要是富士康你雇哪個?GPU就是這樣,用很多簡單的計(jì)算單元去完成大量的計(jì)算任務(wù),純粹的人海戰(zhàn)術(shù)。這種策略基于一個前提,就是小學(xué)生A和小學(xué)生B的工作沒有什么依賴性,是互相獨(dú)立的。很多涉及到大量計(jì)算的問題基本都有這種特性,比如你說的破解密碼,挖礦和很多圖形學(xué)的計(jì)算。這些計(jì)算可以分解為多個相同的簡單小任務(wù),每個任務(wù)就可以分給一個小學(xué)生去做。但還有一些任務(wù)涉及到“流”的問題。比如你去相親,雙方看著順眼才能繼續(xù)發(fā)展。總不能你這邊還沒見面呢,那邊找人把證都給領(lǐng)了。這種比較復(fù)雜的問題都是CPU來做的。
總而言之,CPU和GPU因?yàn)樽畛跤脕硖幚淼娜蝿?wù)就不同,所以設(shè)計(jì)上有不小的區(qū)別。而某些任務(wù)和GPU最初用來解決的問題比較相似,所以用GPU來算了。GPU的運(yùn)算速度取決于雇了多少小學(xué)生,CPU的運(yùn)算速度取決于請了多么厲害的教授。教授處理復(fù)雜任務(wù)的能力是碾壓小學(xué)生的,但是對于沒那么復(fù)雜的任務(wù),還是頂不住人多。當(dāng)然現(xiàn)在的GPU也能做一些稍微復(fù)雜的工作了,相當(dāng)于升級成初中生高中生的水平。但還需要CPU來把數(shù)據(jù)喂到嘴邊才能開始干活,究竟還是靠CPU來管的。
什么類型的程序適合在GPU上運(yùn)行?
(1)計(jì)算密集型的程序。所謂計(jì)算密集型(Compute-intensive)的程序,就是其大部分運(yùn)行時(shí)間花在了寄存器運(yùn)算上,寄存器的速度和處理器的速度相當(dāng),從寄存器讀寫數(shù)據(jù)幾乎沒有延時(shí)。可以做一下對比,讀內(nèi)存的延遲大概是幾百個時(shí)鐘周期;讀硬盤的速度就不說了,即便是SSD, 也實(shí)在是太慢了。
(2)易于并行的程序。GPU其實(shí)是一種SIMD(Single Instruction Multiple Data)架構(gòu), 他有成百上千個核,每一個核在同一時(shí)間最好能做同樣的事情。
CPU會利用較高的主頻、cache、分支預(yù)測等技術(shù),使處理每條指令所需的時(shí)間盡可能少,從而減低具有復(fù)雜跳轉(zhuǎn)分支程序執(zhí)行所需的時(shí)間。GPU則通過數(shù)量喪心病狂的流處理器實(shí)現(xiàn)大量線程并行,使同時(shí)走一條指令的數(shù)據(jù)變多,從而提高數(shù)據(jù)的吞吐量。
舉個GPU通用計(jì)算教材上比較常見的例子,一個向量相加的程序,你可以讓CPU跑一個循環(huán),每個循環(huán)對一個分量做加法,也可以讓GPU同時(shí)開大量線程,每個并行的線程對應(yīng)一個分量的相加。CPU跑循環(huán)的時(shí)候每條指令所需時(shí)間一般低于GPU,但GPU因?yàn)榭梢蚤_大量的線程并行地跑,具有SIMD(準(zhǔn)確地說是SIMT)的優(yōu)勢。
再以挖BIT幣舉例:

比特幣的挖礦和節(jié)點(diǎn)軟件是基于P2P網(wǎng)絡(luò)、數(shù)字簽名、密碼學(xué)證據(jù)來發(fā)起和驗(yàn)證交易的。節(jié)點(diǎn)向網(wǎng)絡(luò)廣播交易,這些廣播出來的交易在經(jīng)過礦工的驗(yàn)證后,礦工用自己的工作證明結(jié)果來表達(dá)確認(rèn),確認(rèn)后的交易會被打包到數(shù)據(jù)塊中,數(shù)據(jù)塊會串起來形成連續(xù)的數(shù)據(jù)塊鏈。
每一個比特幣的節(jié)點(diǎn)都會收集所有尚未確認(rèn)的交易,并將其歸集到一個數(shù)據(jù)塊中,這個數(shù)據(jù)塊會和前面一個數(shù)據(jù)塊集成在一起。礦工節(jié)點(diǎn)會附加一個隨機(jī)調(diào)整數(shù),并計(jì)算前一個數(shù)據(jù)塊的SHA-256哈希運(yùn)算值。挖礦節(jié)點(diǎn)不斷重復(fù)進(jìn)行嘗試,直到它找到的隨機(jī)調(diào)整數(shù)使得產(chǎn)生的哈希值低于某個特定的目標(biāo)。
如果希望判定一個人提供的的信息是本著正常使用,具備一定價(jià)值的。那么我們傾向認(rèn)為提供這個信息的人,愿意為此付出一定工作量來證明他的誠實(shí)。假如有一種機(jī)制,能夠容易的證明提供信息的人為此付出了一定工作量,那么此信息是可以接受,并被認(rèn)為合理的。
比如,我收郵件的時(shí)候,做了一個規(guī)定:“把郵件內(nèi)容數(shù)據(jù),加入一個隨機(jī)數(shù),求一個sha256散列數(shù)值。這個散列值一共256bit 。前20bit 必須都為0”.這樣,要給我發(fā)信的人,就必須反復(fù)嘗試一個隨機(jī)數(shù),以保證郵件內(nèi)容數(shù)據(jù)加上這個隨機(jī)數(shù),能夠產(chǎn)生sha256 的結(jié)果------前20bit 都是0.(這個計(jì)算過程本身毫無意義)。如何產(chǎn)生出指定要求的整數(shù)?完全靠運(yùn)氣和CPU 運(yùn)算時(shí)間。這就是一個工作量。工作本身毫無意義。但是如果誰愿意付出這個工作量,就意味著他給我的郵件多半是有意義的。這就叫“工作量證明”。也就是意味著這個人很有可能是誠實(shí)的。這里把郵件換成Block也是等效的。這個機(jī)制被廣泛用于防止垃圾郵件等。因?yàn)槿喊l(fā)垃圾郵件的人,不可能有那么多時(shí)間去給每個人算一個毫無意義的數(shù)字,浪費(fèi)時(shí)間,降低發(fā)垃圾郵件的效率。挖礦的目的是確認(rèn)交易。尋找隨機(jī)數(shù)的過程是為了保證每一個挖礦節(jié)點(diǎn)不會往外發(fā)送垃圾block。發(fā)送的BlockId是這個Block的Hash,它必然是首20bit為0的。
可以預(yù)見的是對于比特幣的Hash計(jì)算而言,它幾乎都是獨(dú)立并發(fā)的整數(shù)計(jì)算,GPU簡直就是為了這個而設(shè)計(jì)生產(chǎn)出來的。相比較CPU可憐的2-8線程和長度驚人的控制判斷和調(diào)度分支,GPU可以輕易的進(jìn)行數(shù)百個線程的整數(shù)計(jì)算并發(fā)(無需任何判斷的無腦暴力破解乃是A卡的強(qiáng)項(xiàng))。 OpenCL可以利用GPU在片的大量unified shader都可以用來作為整數(shù)計(jì)算的資源。而A卡的shader(流處理器)資源又是N的數(shù)倍(同等級別的卡)。
比特幣早期通過CPU來獲取,而隨著GPU通用計(jì)算的優(yōu)勢不斷顯現(xiàn)以及GPU速度的不斷發(fā)展,礦工們逐漸開始使用GPU取代CPU進(jìn)行挖礦。前面我們已經(jīng)介紹,比特幣挖礦采用的是SHA-256哈希值運(yùn)算,這種算法會進(jìn)行大量的32位整數(shù)循環(huán)右移運(yùn)算。有趣的是,這種算法操作在AMD GPU里可以通過單一硬件指令實(shí)現(xiàn),而在NVIDIA GPU里則需要三次硬件指令來模擬,僅這一條就為AMD GPU帶來額外的1.7倍的運(yùn)算效率優(yōu)勢。憑借這種優(yōu)勢,AMD GPU因此深受廣大礦工青睞。
現(xiàn)在你知道為什么AMD搞得跟藍(lán)翔技校似得了吧?