131 1300 0010
人工智能芯片目前有兩種發展路徑:一種是延續傳統計算架構,加速硬件計算能力,主要以 3 種類型的芯片為代表,即 GPU、 FPGA、 ASIC,但CPU依舊發揮著不可替代的作用;另一種是顛覆經典的馮·諾依曼計算架構,采用類腦神經結構來提升計算能力,以IBM TrueNorth 芯片為代表。
傳統 CPU
計算機工業從1960年代早期開始使用CPU這個術語。迄今為止,CPU從形態、設計到實現都已發生了巨大的變化,但是其基本工作原理卻一直沒有大的改變。 通常 CPU 由控制器和運算器這兩個主要部件組成。 傳統的 CPU 內部結構圖如圖所示:
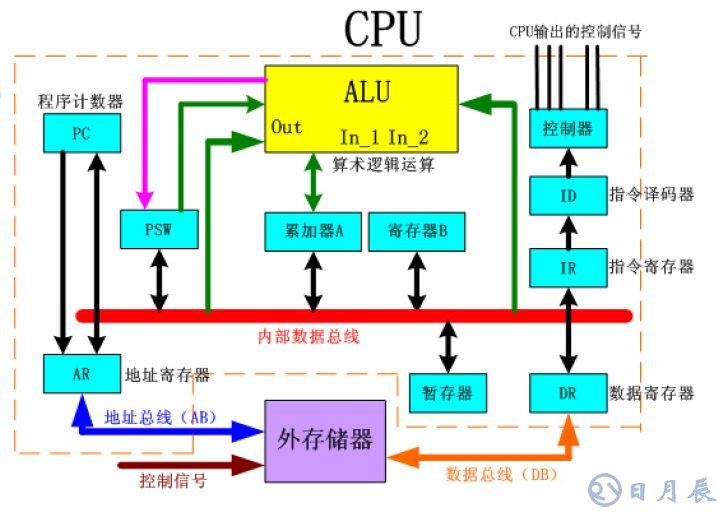
傳統CPU內部結構圖(ALU計算模塊)
從圖中我們可以看到:實質上僅單獨的ALU模塊(邏輯運算單元)是用來完成數據計算的,其他各個模塊的存在都是為了保證指令能夠一條接一條的有序執行。這種通用性結構對于傳統的編程計算模式非常適合,同時可以通過提升CPU主頻(提升單位時間內執行指令的條數)來提升計算速度。 但對于深度學習中的并不需要太多的程序指令、 卻需要海量數據運算的計算需求, 這種結構就顯得有些力不從心。尤其是在功耗限制下, 無法通過無限制的提升 CPU 和內存的工作頻率來加快指令執行速度, 這種情況導致 CPU 系統的發展遇到不可逾越的瓶頸。
并行加速計算的GPU
GPU 作為最早從事并行加速計算的處理器,相比 CPU 速度快, 同時比其他加速器芯片編程靈活簡單。
傳統的 CPU 之所以不適合人工智能算法的執行,主要原因在于其計算指令遵循串行執行的方式,沒能發揮出芯片的全部潛力。與之不同的是, GPU 具有高并行結構,在處理圖形數據和復雜算法方面擁有比 CPU 更高的效率。對比 GPU 和 CPU 在結構上的差異, CPU大部分面積為控制器和寄存器,而 GPU 擁有更ALU(邏輯運算單元)用于數據處理,這樣的結構適合對密集型數據進行并行處理, CPU 與 GPU 的結構對比如圖 所示。
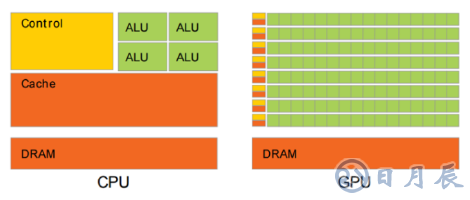
CPU及GPU結構對比圖
程序在 GPU系統上的運行速度相較于單核 CPU往往提升幾十倍乃至上千倍。隨著英偉達、 AMD 等公司不斷推進其對 GPU 大規模并行架構的支持,面向通用計算的 GPU(即GPGPU,通用計算圖形處理器)已成為加速可并行應用程序的重要手段,GPU 的發展歷程可分為 3 個階段:
第一代GPU(1999年以前),部分功能從CPU分離 , 實現硬件加速 , 以GE(GEOMETRY ENGINE)為代表,只能起到 3D 圖像處理的加速作用,不具有軟件編程特性。
第二代 GPU(1999-2005 年), 實現進一步的硬件加速和有限的編程性。 1999年,英偉達發布了“專為執行復雜的數學和幾何計算的” GeForce256 圖像處理芯片,將更多的晶體管用作執行單元, 而不是像 CPU 那樣用作復雜的控制單元和緩存,將(TRANSFORM AND LIGHTING) 等功能從 CPU 分離出來,實現了快速變換,這成為 GPU 真正出現的標志。之后幾年, GPU 技術快速發展,運算速度迅速超過 CPU。 2001年英偉達和ATI 分別推出的GEFORCE3和RADEON 8500,圖形硬件的流水線被定義為流處理器,出現了頂點級可編程性,同時像素級也具有有限的編程性,但 GPU 的整體編程性仍然比較有限。
第三代 GPU(2006年以后), GPU實現方便的編程環境創建, 可以直接編寫程序。 2006年英偉達與ATI分別推出了CUDA (Compute United Device Architecture,計算統一設備架構)編程環境和CTM(CLOSE TO THE METAL)編程環境, 使得 GPU 打破圖形語言的局限成為真正的并行數據處理超級加速器。
2008年,蘋果公司提出一個通用的并行計算編程平臺 OPENCL(開放運算語言),與CUDA綁定在英偉達的顯卡上不同,OPENCL 和具體的計算設備無關。
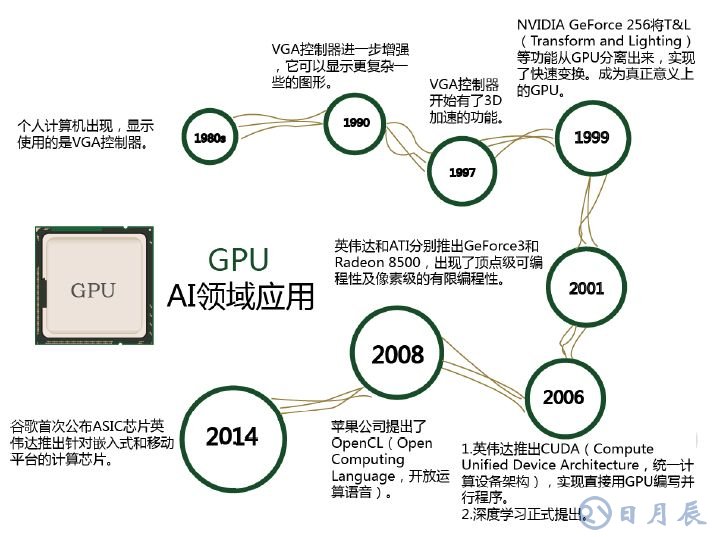
GPU芯片的發展階段
目前, GPU 已經發展到較為成熟的階段。谷歌、 FACEBOOK、微軟、 Twtter和百度等公司都在使用GPU 分析圖片、視頻和音頻文件,以改進搜索和圖像標簽等應用功能。此外,很多汽車生產商也在使用GPU芯片發展無人駕駛。 不僅如此, GPU也被應用于VR/AR 相關的產業。
但是 GPU也有一定的局限性。 深度學習算法分為訓練和推斷兩部分, GPU 平臺在算法訓練上非常高效。但在推斷中對于單項輸入進行處理的時候,并行計算的優勢不能完全發揮出來。
半定制化的FPGA
FPGA 是在 PAL、 GAL、 CPLD 等可編程器件基礎上進一步發展的產物。用戶可以通過燒入 FPGA 配置文件來定義這些門電路以及存儲器之間的連線。這種燒入不是一次性的,比如用戶可以把 FPGA 配置成一個微控制器 MCU,使用完畢后可以編輯配置文件把同一個FPGA 配置成一個音頻編解碼器。因此, 它既解決了定制電路靈活性的不足,又克服了原有可編程器件門電路數有限的缺點。
FPGA可同時進行數據并行和任務并行計算,在處理特定應用時有更加明顯的效率提升。對于某個特定運算,通用 CPU可能需要多個時鐘周期,而 FPGA 可以通過編程重組電路,直接生成專用電路,僅消耗少量甚至一次時鐘周期就可完成運算。
此外,由于 FPGA的靈活性,很多使用通用處理器或 ASIC難以實現的底層硬件控制操作技術, 利用 FPGA 可以很方便的實現。這個特性為算法的功能實現和優化留出了更大空間。同時FPGA 一次性成本(光刻掩模制作成本)遠低于ASIC,在芯片需求還未成規模、深度學習算法暫未穩定, 需要不斷迭代改進的情況下,利用 FPGA 芯片具備可重構的特性來實現半定制的人工智能芯片是最佳選擇之一。
功耗方面,從體系結構而言, FPGA 也具有天生的優勢。傳統的馮氏結構中,執行單元(如 CPU 核)執行任意指令,都需要有指令存儲器、譯碼器、各種指令的運算器及分支跳轉處理邏輯參與運行, 而FPGA每個邏輯單元的功能在重編程(即燒入)時就已經確定,不需要指令,無需共享內存,從而可以極大的降低單位執行的功耗,提高整體的能耗比。
由于 FPGA 具備靈活快速的特點, 因此在眾多領域都有替代ASIC 的趨勢。 FPGA 在人工智能領域的應用如圖所示。
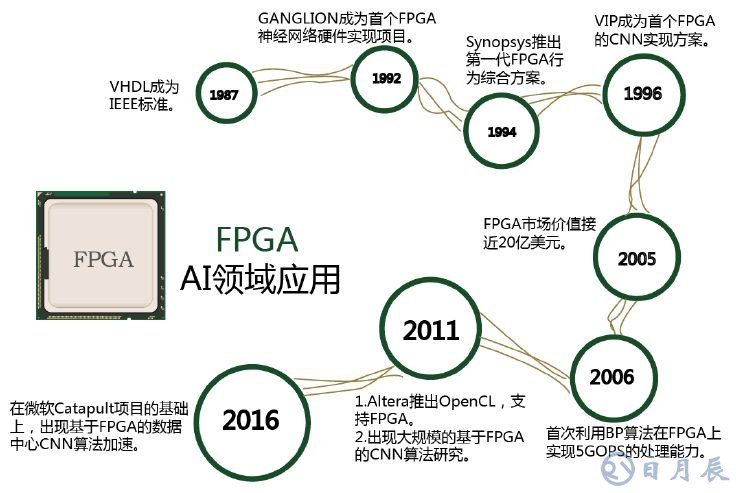
FPGA 在人工智能領域的應用
全定制化的ASIC
目前以深度學習為代表的人工智能計算需求,主要采用GPU、FPGA等已有的適合并行計算的通用芯片來實現加速。在產業應用沒有大規模興起之時,使用這類已有的通用芯片可以避免專門研發定制芯片(ASIC)的高投入和高風險。但是,由于這類通用芯片設計初衷并非專門針對深度學習,因而天然存在性能、 功耗等方面的局限性。隨著人工智能應用規模的擴大,這類問題日益突顯。
GPU作為圖像處理器, 設計初衷是為了應對圖像處理中的大規模并行計算。因此,在應用于深度學習算法時,有三個方面的局限性:
第一:應用過程中無法充分發揮并行計算優勢。 深度學習包含訓練和推斷兩個計算環節, GPU 在深度學習算法訓練上非常高效, 但對于單一輸入進行推斷的場合, 并行度的優勢不能完全發揮。
第二:無法靈活配置硬件結構。 GPU 采用 SIMT 計算模式, 硬件結構相對固定。 目前深度學習算法還未完全穩定,若深度學習算法發生大的變化, GPU 無法像 FPGA 一樣可以靈活的配制硬件結構。
第三:運行深度學習算法能效低于FPGA。
盡管 FPGA 倍受看好,甚至新一代百度大腦也是基于 FPGA 平臺研發,但其畢竟不是專門為了適用深度學習算法而研發,實際應用中也存在諸多局限:
第一:基本單元的計算能力有限。為了實現可重構特性, FPGA 內部有大量極細粒度的基本單元,但是每個單元的計算能力(主要依靠 LUT 查找表)都遠遠低于 CPU 和 GPU 中的 ALU 模塊。
第二:計算資源占比相對較低。 為實現可重構特性, FPGA 內部大量資源被用于可配置的片上路由與連線。
第三:速度和功耗相對專用定制芯片(ASIC)仍然存在不小差距。
第四,:FPGA 價格較為昂貴。在規模放量的情況下單塊 FPGA 的成本要遠高于專用定制芯片。
因此,隨著人工智能算法和應用技術的日益發展,以及人工智能專用芯片 ASIC產業環境的逐漸成熟, 全定制化人工智能 ASIC也逐步體現出自身的優勢,從事此類芯片研發與應用的國內外比較有代表性的公司如圖所示。
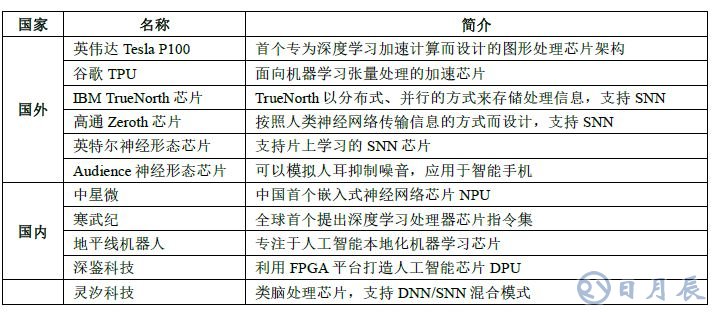
人工智能專用芯片研發情況一覽
深度學習算法穩定后, AI 芯片可采用ASIC設計方法進行全定制, 使性能、功耗和面積等指標面向深度學習算法做到最優。
類腦芯片
類腦芯片不采用經典的馮·諾依曼架構, 而是基于神經形態架構設計,以IBM Truenorth為代表。 IBM 研究人員將存儲單元作為突觸、計算單元作為神經元、傳輸單元作為軸突搭建了神經芯片的原型。
目前, Truenorth用三星 28nm功耗工藝技術,由 54億個晶體管組成的芯片構成的片上網絡有4096個神經突觸核心,實時作業功耗僅為70mW。由于神經突觸要求權重可變且要有記憶功能, IBM采用與CMOS工藝兼容的相變非易失存儲器(PCM)的技術實驗性的實現了新型突觸,加快了商業化進程。

